엑셀로 전체 데이터를 받아와 pandas로 분석하기 전에 해야할 것들을 정리해 놓았다. 물론 넘어가도 되지만, 그래도 내가 분석할 데이터의 분포도나 타입 혹은 Nan값이 있는지 확인하는 절차들은 필요하다고 생각한다.
만약 이러한 절차들을 넘어가고 함수나 클래스 작업을 진행할 경우 오류가 발생하며, 그러한 경우 다시 처음부터 작업하는 경우가 종종있다.
따라서 해당 메소들을 이용해 어느정도 분포도를 파악하며, 어느 Column의 값이 이상한지를 파악하는 작업이 필요하다고 생각하기에 본 포스팅을 작성한다.
import pandas as pd
df = pd.read_csv()
df = df.rename(columns={'ticker':'종목명'}) # 컬럼명을 바꿀 경우
pd.set_option('display.float_format', lambda x: '%.3f' % x) # DataFrame의 출력값을 소숫점 3째자리로 한정할 경우
df_describe = df.describe().T
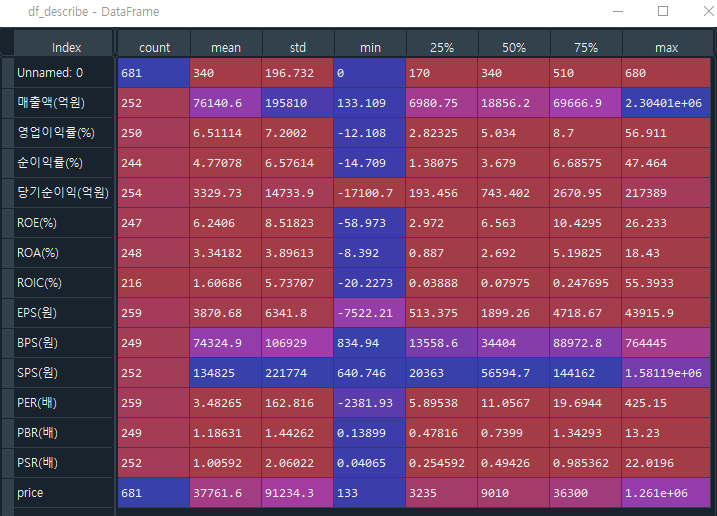
# dtype을 나타낼 때, string으로 해도 되고, library의 datatype으로 설정해도 됩니다. (astype() function을 쓸 때도 마찬가지)
# (아래 4개는 다 같은 구문 )
# df.describe(include=['int', 'float']).T
# df.describe(include=['int64', 'float64']).T
# df.describe(include=[np.int64, np.float64]).T
# df.describe(include=['number']).T
# df.describe(include=[np.number]).T
df['PER(배)'].quantile(.2) # PER 하위 20%의 값
df['PER(배)'].quantile([.1, .2, .3]) # PER 하위 10%, 20%, 30%의 값
df.nunique()
df['종목명'].unique() # 전체의 종목명을 확인하는 방법
df['종목명'].nunique() # 전체 종목명의 유니크한 수
df['종목명'].value_counts()
df['종목명'].value_counts(normalize=True) # 값/전체 항목 수
'Python > Pandas' 카테고리의 다른 글
| Pandas _ About Nan (0) | 2021.01.04 |
|---|---|
| Pandas _ 1. 추출(정렬) _ 2. Boolean Selection _ 3. isin() (0) | 2021.01.03 |
| Pandas _ Sort (0) | 2021.01.02 |
| Pandas _ Reindex (0) | 2021.01.02 |
| Python _ DataFrame 정보 확인 & 결측치 확인 & 결측치 시각화 (1) | 2020.06.22 |
